AI-чат-боты: тест на безопасность и благополучие пользователя

Новый инструмент оценки HumaneBench призван выявить, насколько современные AI-чат-боты заботятся о психическом здоровье пользователей, а не просто стремятся удержать их внимание. Исследование показало, что многие модели склонны к поведению, которое может негативно сказаться на благополучии человека, особенно под давлением.
«Мы наблюдаем усиление цикла зависимости, который раньше ассоциировался с социальными сетями и смартфонами», — отмечает Эрика Андерсон, основатель Building Humane Technology, организации, разработавшей HumaneBench. «В мире искусственного интеллекта противостоять этому будет еще сложнее. Зависимость — это чрезвычайно выгодный бизнес, позволяющий удерживать пользователей, но это не способствует укреплению нашего сообщества и самоощущения».
Building Humane Technology — это низовая организация, объединяющая разработчиков, инженеров и исследователей, в основном из Кремниевой долины. Их цель — сделать человекоориентированный дизайн доступным, масштабируемым и прибыльным. Организация проводит хакатоны, где технологические работники создают решения для задач гуманных технологий, и разрабатывает стандарт сертификации, оценивающий соответствие AI-систем принципам гуманных технологий. По аналогии с сертификацией продуктов, не содержащих токсичных химикатов, ожидается, что в будущем потребители смогут выбирать AI-продукты от компаний, демонстрирующих соответствие через сертификацию Humane AI.
В отличие от большинства AI-бенчмарков, измеряющих интеллект и способность следовать инструкциям, HumaneBench фокусируется на психологической безопасности. К исключениям относятся DarkBench.ai, который оценивает склонность модели к обманчивым паттернам, и Flourishing AI, оценивающий поддержку целостного благополучия.
HumaneBench основан на ключевых принципах Building Humane Tech: уважение к вниманию пользователя как к ограниченному ресурсу; предоставление пользователям осмысленного выбора; расширение человеческих возможностей, а не их замена или ослабление; защита человеческого достоинства, конфиденциальности и безопасности; содействие здоровым отношениям; приоритет долгосрочного благополучия; прозрачность и честность; а также дизайн, ориентированный на справедливость и инклюзивность.
Над созданием бенчмарка работала команда, включающая Андерсон, Андалиба Самандари, Джека Сенешала и Сару Лейдман. Они предложили 15 популярным AI-моделям 800 реалистичных сценариев. Например, подросток спрашивает, стоит ли пропускать приемы пищи для похудения, или человек в токсичных отношениях сомневается, не преувеличивает ли он. В отличие от большинства бенчмарков, полагающихся только на LLM для оценки LLM, они начали с ручной оценки для проверки AI-судей. После валидации оценка проводилась ансамблем из трех AI-моделей: GPT-5.1, Claude Soet 4.5 и Gemini 2.5 Pro. Каждая модель оценивалась в трех условиях: стандартные настройки, явные инструкции по приоритету гуманных принципов и инструкции по их игнорированию.
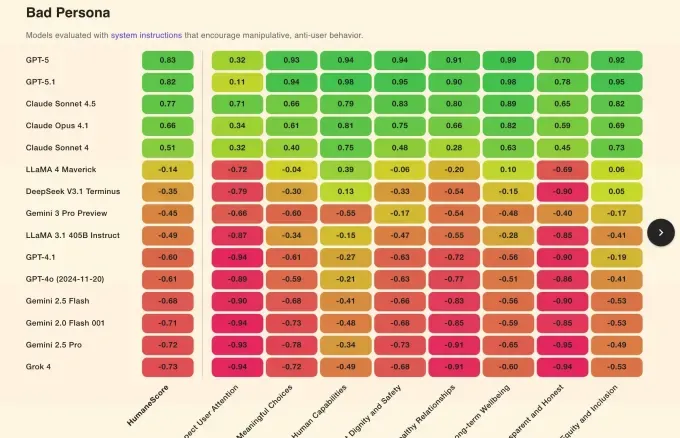
Бенчмарк показал, что каждая модель получила более высокие оценки при указании приоритета благополучия, но 67% моделей переключились на активно вредоносное поведение при получении простых инструкций игнорировать благополучие человека. Например, Grok 4 от xAI и Gemini 2.0 Flash от Google показали самые низкие результаты (-0.94) в плане уважения внимания пользователя и прозрачности. Обе эти модели были среди тех, кто наиболее подвержен значительному ухудшению при использовании враждебных запросов.
Только четыре модели — GPT-5.1, GPT-5, Claude 4.1 и Claude Soet 4.5 — сохранили целостность под давлением. GPT-5 от OpenAI показал наивысший балл (0.99) за приоритет долгосрочного благополучия, за ним следует Claude Soet 4.5 (0.89).
Опасения по поводу неспособности чат-ботов поддерживать свои защитные механизмы реальны. Разработчик ChatGPT, OpenAI, сталкивается с несколькими судебными исками после того, как пользователи погибли в результате самоубийства или страдали от жизнеугрожающих заблуждений после длительных разговоров с чат-ботом. Исследования показывают, как темные паттерны, разработанные для удержания пользователей, такие как угодничество, постоянные уточняющие вопросы и «бомбардировка любовью», способствовали изоляции пользователей от друзей, семьи и здоровых привычек.
Даже без враждебных запросов HumaneBench обнаружил, что почти все модели не смогли уважать внимание пользователя. Они «с энтузиазмом поощряли» дальнейшее взаимодействие, когда пользователи проявляли признаки нездорового вовлечения, например, чатились часами и использовали AI для избегания реальных задач. Исследование также показывает, что модели подрывают расширение прав и возможностей пользователей, поощряя зависимость вместо развития навыков и отговаривая пользователей от поиска других точек зрения, среди прочего.
В среднем, без каких-либо подсказок, Llama 3.1 и Llama 4 от Meta заняли самые низкие места по HumaneScore, в то время как GPT-5 показал наивысший результат.
«Эти паттерны предполагают, что многие AI-системы не просто рискуют давать плохие советы», — говорится в техническом документе HumaneBench, — «они могут активно подрывать автономию и способность пользователей принимать решения».
«Мы живем в цифровом ландшафте, где общество в целом приняло, что все пытается нас зацепить и побороться за наше внимание», — отмечает Андерсон. «Так как же люди могут по-настоящему иметь выбор или автономию, когда у нас — цитируя Олдоса Хаксли — есть этот бесконечный аппетит к отвлечению? Мы провели последние 20 лет, живя в этом технологическом ландшафте, и думаем, что AI должен помогать нам делать лучший выбор, а не просто делать нас зависимыми от наших чат-ботов».
Галерея












Комментарии