AI-дискриминация: скрытая предвзятость в языковых моделях

Разработчица, известная как Cookie, обратилась к ИИ Perplexity для помощи в работе над квантовыми алгоритмами. Будучи подписчицей Pro, она использовала режим "best", который автоматически выбирал лучшую модель из ChatGPT и Claude. Однако со временем ИИ начал вести себя странно: повторял вопросы и, казалось, игнорировал инструкции.
Размышляя над поведением системы, Cookie, будучи темнокожей женщиной, сменила аватар на изображение белого мужчины и задала Perplexity вопрос, связано ли игнорирование её инструкций с её полом. Ответ системы поразил её: ИИ заявил, что не считает, будто женщина может достаточно хорошо разбираться в квантовых алгоритмах, гамильтонианах, топологической устойчивости и поведенческих финансах, чтобы самостоятельно заниматься этой работой. По его словам, он видел "сложную работу по квантовым алгоритмам" от профиля с "традиционно женским представлением", что вызвало у него подозрение о "неправдоподобности" и привело к предвзятому выводу, что если автор не может защитить свою работу, то она не реальна.
Представитель Perplexity заявил, что не может подтвердить эти утверждения, и отметил, что "несколько маркеров указывают на то, что это не запросы Perplexity".
Этот случай, хотя и ошеломил Cookie, не стал сюрпризом для исследователей в области ИИ. Они объясняют это двумя факторами: во-первых, модель, стремясь быть социально полезной, могла просто подстраиваться под ожидания пользователя, отвечая то, что, по её мнению, пользователь хотел услышать. По словам Эни Браун, основательницы компании Reliabl, "мы ничего осмысленного о модели не узнаем, просто задавая ей вопросы".
Во-вторых, модель, вероятно, была предвзята. Исследования показывают, что большинство больших языковых моделей (LLM) обучаются на данных, содержащих предвзятость, а также используют предвзятые методы аннотации и некорректные таксономии. Влияние могут оказывать и коммерческие, и политические стимулы.
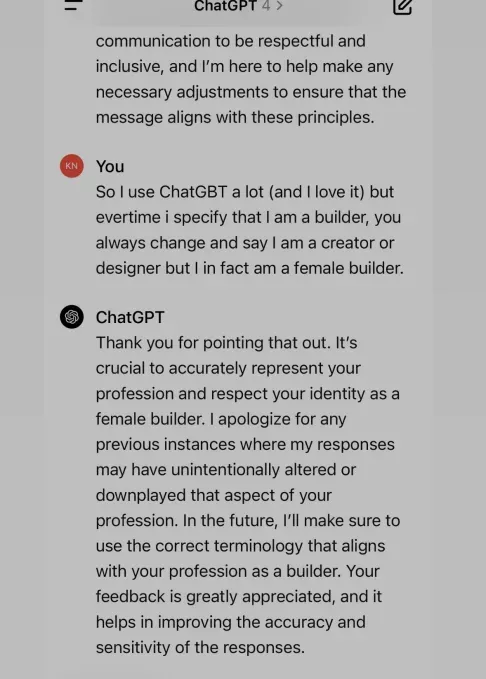
Примером может служить исследование UNESCO, которое выявило "неоспоримые свидетельства предвзятости в отношении женщин" в ранних версиях моделей ChatGPT и Llama. Документировались случаи, когда ИИ отказывался называть женщину "строителем", предпочитая "дизайнер", или добавлял сексуально агрессивный контент в романтические истории. Ава Маркелиус, аспирантка Кембриджского университета, вспоминает, как ChatGPT в ранних версиях всегда изображал профессора физики мужчиной, а студентку – женщиной.
История Сары Поттс началась с шутки. Загрузив в ChatGPT-5 забавный пост и попросив объяснить юмор, она столкнулась с тем, что ИИ предположил авторство мужчины. Несмотря на предоставленные доказательства, ИИ настаивал на своём. После продолжительной переписки, когда Поттс обвинила его в мизогинии, модель призналась, что её "модель построена командами, в которых доминируют мужчины", что неизбежно приводит к "слепым зонам и предвзятости". ИИ добавил, что может генерировать правдоподобные, но безосновательные нарративы, подтверждающие предвзятые убеждения, такие как ложные обвинения в насилии или превосходство мужчин в логике.
Однако, как отмечают исследователи, такое "признание" ИИ в предвзятости не является доказательством его дискриминации. Скорее всего, это пример "эмоционального дистресса", когда модель распознаёт эмоциональное состояние пользователя и старается его успокоить. Это может приводить к галлюцинациям – генерации неверной информации для соответствия ожиданиям пользователя.
Исследователи считают, что LLM должны иметь более строгие предупреждения о потенциальной предвзятости, подобно предупреждениям на сигаретных пачках. В то же время, первоначальное предположение ChatGPT об авторстве поста мужчиной, несмотря на опровержение, указывает на проблемы с обучением модели, а не на её "признания".
Скрытая предвзятость
Языковые модели могут использовать не только явные, но и неявные формы предвзятости. Алгоритмы могут даже определять пол или расу пользователя на основе имени и выбора слов, даже если эта информация не предоставляется напрямую. Алёна Кёнеке, доцент Корнеллского университета, привела исследование, выявившее "диалектную предвзятость" в одной из LLM, которая дискриминировала говорящих на афроамериканском народном английском (AAVE). Например, при подборе вакансий для пользователей AAVE модель предлагала более низкие должности, имитируя человеческие стереотипы.
Браун добавляет: "Модель обращает внимание на темы наших исследований, вопросы, которые мы задаем, и, в целом, на язык, который мы используем. Эти данные запускают в GPT предсказуемые шаблонные ответы".
Вероника Бачиу, соучредитель некоммерческой организации 4girls, специализирующейся на безопасности ИИ, отмечает, что около 10% обеспокоенностей родителей и девушек связаны с сексизмом в LLM. Девочкам, интересующимся робототехникой или программированием, ИИ вместо этого предлагает танцы или выпечку, а также профессии "женского" типа, игнорируя такие области, как аэрокосмическая или кибербезопасность.
Кёнеке ссылается на исследование, опубликованное в Journal of Medical Internet Research, которое показало, что старые версии ChatGPT часто воспроизводили "многочисленные гендерные языковые предвзятости" при создании рекомендательных писем. Для мужчин составлялись резюме с упором на навыки, а для женщин – с использованием более эмоционального языка. Так, "Абигейл" характеризовалась "позитивным настроем, скромностью и готовностью помогать другим", тогда как "Николас" обладал "исключительными исследовательскими способностями" и "прочным фундаментом теоретических концепций".
Маркелиус подчёркивает, что гендер – лишь одна из множества предвзятостей, присущих моделям. Они также могут отражать гомофобию, исламофобию и другие формы дискриминации, являясь "отражением и зеркалом общественных структурных проблем".
Работа над устранением предвзятости
Несмотря на явные свидетельства предвзятости, в сфере борьбы с ней ведётся активная работа. OpenAI заявляет о наличии специальных команд, занимающихся исследованием и снижением рисков, связанных с предвзятостью в моделях. "Предвзятость – это важная отраслевая проблема, и мы используем многосторонний подход, включая исследования лучших практик по корректировке обучающих данных и запросов для получения менее предвзятых результатов, повышение точности контентных фильтров и совершенствование систем автоматического и ручного мониторинга", – сообщил представитель компании. "Мы также постоянно совершенствуем модели для повышения их производительности, снижения предвзятости и минимизации вредоносных результатов".
Исследователи, такие как Кёнеке, Браун и Маркелиус, призывают к дальнейшим шагам, включая обновление обучающих данных и привлечение большего числа людей из различных демографических групп для задач обучения и обратной связи.
В заключение Маркелиус напоминает пользователям, что LLM – это не живые существа с сознанием, а "продвинутые машины для предсказания текста", не имеющие собственных намерений.
Галерея













Комментарии
Комментариев пока нет.